


In today's technology landscape, working in an AI-related role or being an AI entrepreneur often elicits admiration. AI represents cutting-edge technology, advanced productivity, and novel business models reminiscent of the early days of the internet in the 1990s. However, achieving the profit margins of traditional software or SaaS companies poses a significant challenge for AI firms. AI companies typically face lower gross profit margins and encounter difficulties in scaling their operations. While some classify AI companies as software firms, I believe they resemble innovative laboratories. AI development involves a scientific experiment-like process, encompassing data collection, testing, validation, and continuous optimization. In contrast, software companies embody systematic thinking and an engineering approach. As OpenAI CEO Sam Altman astutely noted, “building AGI is a scientific problem, while building superintelligence is an engineering problem[1]”.
In software development, there is a higher level of certainty compared to AI. Once the market positioning and system architecture of a product are established, new features can be gradually added through iterative and agile processes, leading to the realization of the complete product vision. This process involves continuous user interaction, feedback collection, and optimization of features and user experience. Experiments in this context primarily revolve around comparative analyses, often utilizing A/B testing.
Acknowledging the challenges and discussing the profit margins and scalability of AI companies does not undermine the value that AI brings to businesses. From traditional machine learning to the recent surge in transformer-based models, AI has demonstrated remarkable results and significant commercial value. However, as we strive to build efficient AI companies, it is crucial to address the challenges associated with the long-tail distribution problem.
The long tail concept refers to the less common or infrequent events, values, or categories in a distribution curve. It represents the extended tail on the right side of the distribution, where rare events occur with relatively high frequency compared to the more common or central portion. Coined by Chris Anderson in "The Long Tail: Why the Future of Business Is Selling Less of More," the concept highlights that alongside mainstream events or categories, there is a significant portion occupied by numerous niches or less common occurrences. Graphically, the long tail appears as a gradually declining slope extending to the right of the distribution's peak or mode. The area under the long tail represents the cumulative frequency of these less common events or values.

In the process of building AI applications or products, a common occurrence is the presence of long-tail data in certain categories with limited representation in the available dataset. For instance, in an image classification task, some categories may have a substantial number of training examples (representing the "head" of the distribution), while other categories have relatively fewer examples (representing the "long tail" portion). This characteristic presents challenges in scaling AI applications, leading to a cycle of continuously collecting more training data, performing local data sampling, and retraining models to improve performance on edge cases (the long tail).
The development process of AI resembles scientific experimentation, where gaps in the training dataset are identified through instances of model failures (referred to as "bad cases"), followed by collecting additional data to address those gaps. The complexity of the AI application domain can make filling these gaps a costly endeavor.
Additionally, when training AI models, the dominance of head categories in the long-tail data can result in biased models. This inherent characteristic poses challenges in accurately identifying samples from distant categories, leading to significant performance degradation for the tail-end categories of the AI model. Although rebalancing the training data is a commonly adopted solution, it remains a heuristic and suboptimal approach.
In this realistic context, analyzing the challenges faced by AI companies and exploring potential coping strategies becomes valuable for practical implementation.
Challenge 1: Lower Profit Margins
In various traditional domains of AI technology applications, users exhibit minimal tolerance for incorrect outputs. For instance, bank tellers rely on Optical Character Recognition (OCR) systems to scan customer-filled deposit slips, extract account information, and automatically enter it into the bank's transaction system. Likewise, autonomous vehicles must strictly adhere to laws and safety regulations during highway driving and navigation. While AI demonstrates superior accuracy compared to humans in well-defined tasks, it often falls short when it comes to paying attention to critical contextual information and comprehending long-tail problems, such as temporary handwritten signs placed on roads due to construction. In such cases, human performance frequently surpasses that of AI.
In many real-world application scenarios, the competition for AI is not traditional computer programs but rather human capabilities. When tasks involve fundamental human abilities like perception, humans have proven to be a more cost-effective resource. Achieving relatively accurate results through human involvement often requires smaller cost investments compared to AI solutions. Additionally, AI is often expected to surpass human performance standards. Merely matching human capabilities may not suffice to drive widespread adoption of AI systems, as new approaches must deliver significant improvements to justify transformative changes. Even when AI clearly outperforms humans, it still faces inherent disadvantages.
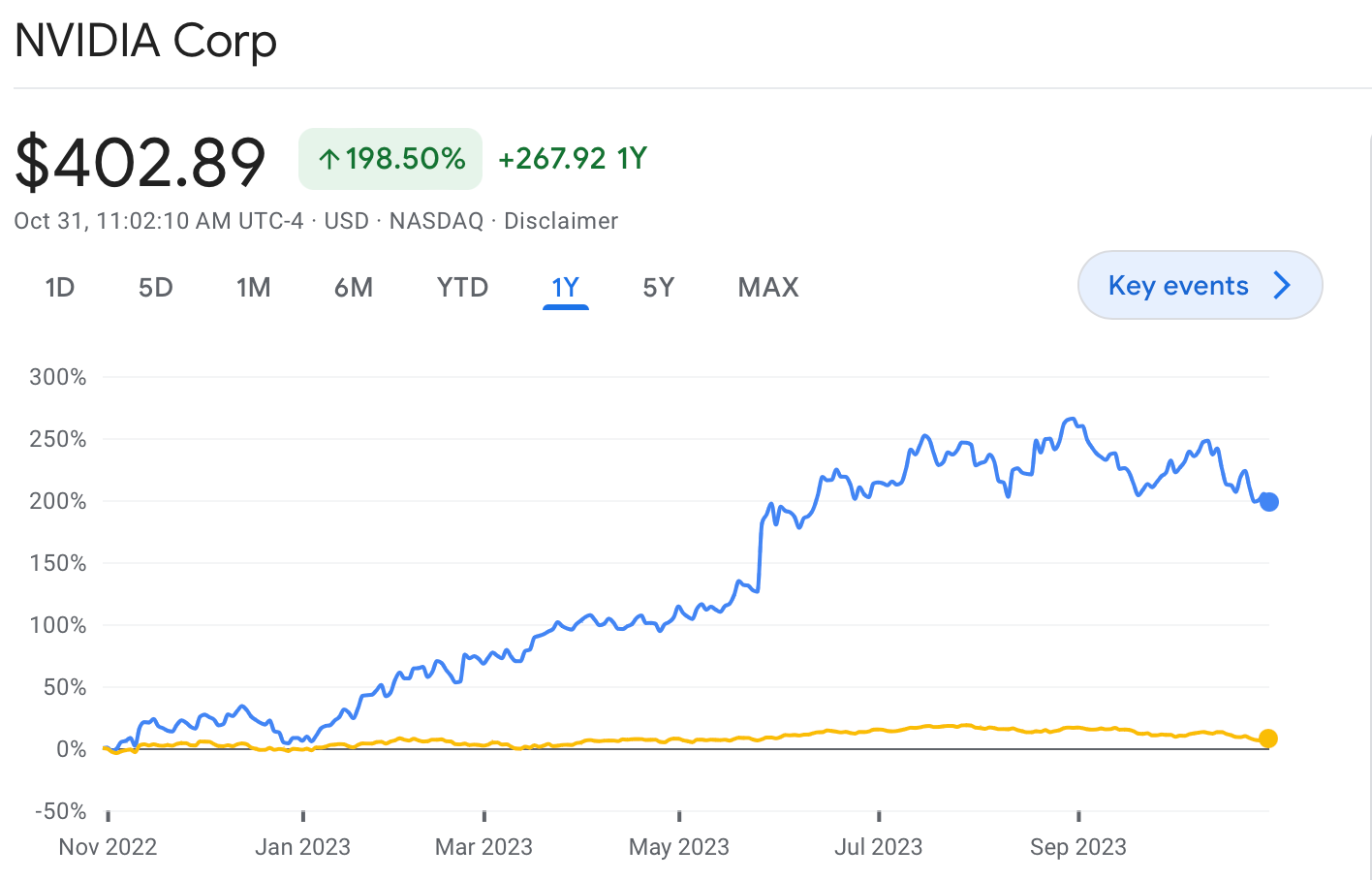
Furthermore, AI does not possess significant cost advantages over humans in achieving relatively accurate business goals. The cost of training a single AI model can be substantial. While the investment in computational resources may be considered a one-time expense, the ongoing cost of retraining is increasingly recognized due to the evolving nature of the data supporting AI models. AI applications often deal with rich media formats like images, audio, or video, which necessitate expensive GPU processors. Additionally, the cost of utilizing cloud services must be considered. In many cases, AI applications must process large files to extract small segments of relevant information, resulting in significant expenses for transferring trained models between cloud regions. The high costs associated with computational power and cloud services required for training and product development across various business scenarios pose significant financial burdens for AI companies. This also partly explains the remarkable increase of 198% in NVIDIA's market value over the past year, while the broader index recorded a modest 8% growth during the same period.
Challenge 2: Difficulty of Scale
The ability of AI companies to achieve economies of scale through processing large volumes of training data is a topic that warrants careful analysis. Economies of scale can be viewed as a competitive advantage stemming from the expansion of operational scale. This concept shares similarities with the "network effect" pursued by platform-based enterprises, which relies on increasing user numbers to create competitive barriers. However, achieving economies of scale in AI is distinct and revolves around data considerations, encompassing the following aspects.
First and foremost, the value derived from data heavily relies on its quality and relevance to the specific problem at hand. Mere accumulation of vast amounts of data does not guarantee exceptional performance. The emphasis should be on acquiring high-quality and meaningful data that aligns with the goals of the application. AI companies should prioritize the pursuit of "high-quality data" rather than solely focusing on accumulating large quantities. A notable example is Scale AI, a startup that has garnered significant recognition in the AI sector by providing high-quality training data to large technology companies, currently valued at $7.3 billion[2].
Secondly, data acquisition can act as a limiting factor in achieving network effects. When data is proprietary or difficult to obtain, it hampers the creation of strong network effects. Additionally, regulations and privacy concerns can impede data sharing, particularly prevalent in the financial industry. While the financial sector possesses substantial user data suitable for AI-driven transformations, its strict regulatory environment and compliance requirements pose challenges for delivering AI solutions. In many instances, AI companies tend to offer more service-oriented products in this industry.
Simultaneously, as the dataset expands, the likelihood of encountering redundant or similar data increases. Adding redundant data may not significantly enhance the overall value or generate new insights, resulting in diminishing returns for incremental data. In certain fields, the marginal utility of additional data decreases, diminishing its impact on improving AI models or generating novel insights.
As the dataset scales up, acquiring unique and high-quality data may become more challenging and expensive. Data collection may necessitate specialized resources, increasing the cost of obtaining additional data. The storage and processing of large volumes of data entail substantial costs, and the infrastructure required for managing and analyzing data will also expand. These challenges can lead to higher expenses, manifesting as a series of "growing pains."
Lastly, while traditional economies of scale typically reduce costs and increase value, the situation with data scale effects is more complex. The cost of adding unique data to a dataset becomes increasingly certain over time, while the potential incremental value derived from that additional data may decrease. Reliance solely on data assets may not suffice to establish a sustainable competitive advantage. AI companies must also develop complementary assets and capabilities, such as proprietary algorithms, domain expertise, customer relationships, or unique processes, to fully leverage the potential of data network effects.
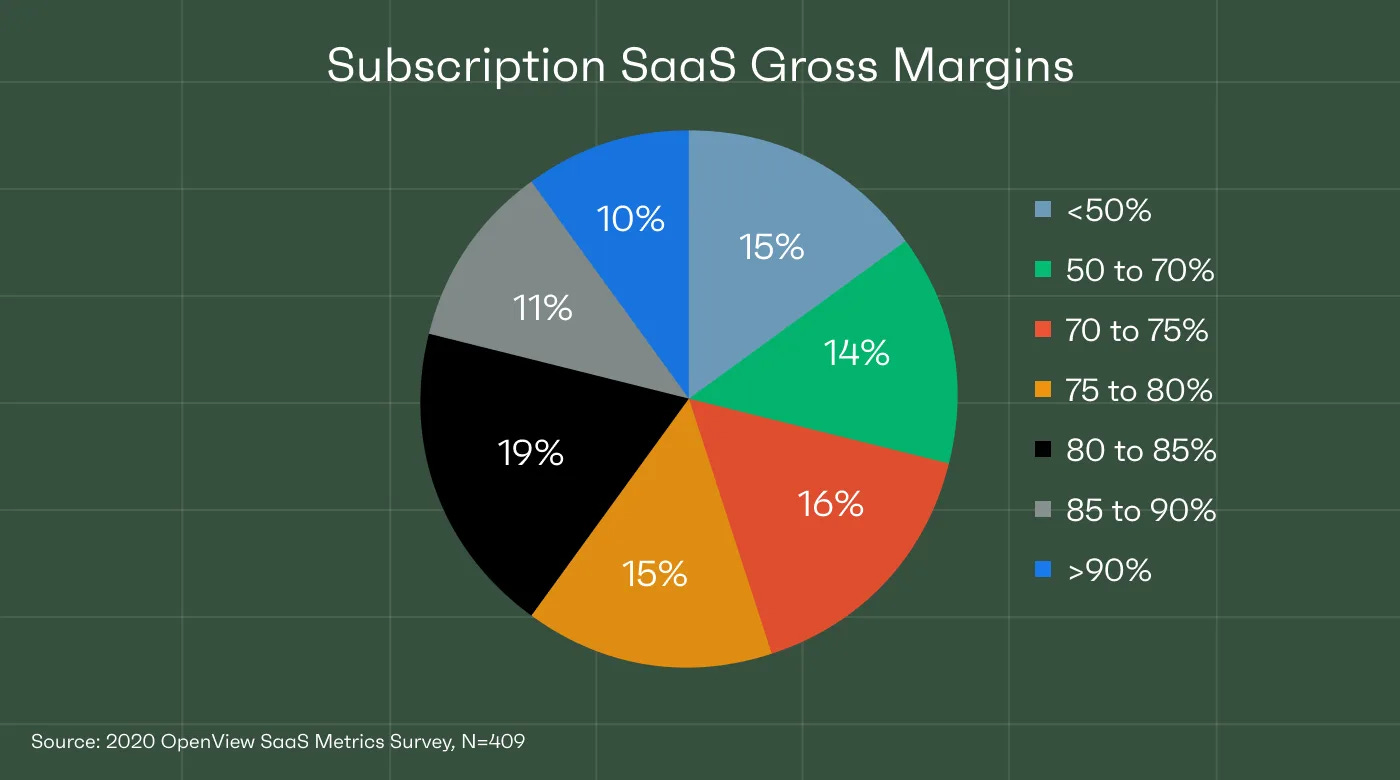
Software, including Software as a Service (SaaS), possesses a distinctive characteristic of being developed once and sold repeatedly. This attribute offers numerous noteworthy business advantages, such as sustainable revenue streams, high gross profit margins (typically ranging from 60% to 80% or higher), and the potential for exponential expansion, particularly in cases where network effects or scale effects come into play. Moreover, software companies can establish robust defensive barriers by owning the intellectual property generated through software development. In contrast, service-based businesses require specialized personnel for each new project and can only sell their services once. Consequently, revenue from service-based businesses is often non-recurring, and gross profit margins typically range from 30% to 50% or lower. Achieving exponential growth in service-based businesses is more challenging, with linear growth being more common. Establishing defensive capabilities in service-based businesses is also more arduous and often relies on brand reputation or providing value-added services to existing customers. Notably, an increasing number of AI companies are displaying a fusion of software and service-based features.
While most AI applications may exhibit the appearance and functionality of traditional software, relying on conventional code for tasks such as user interfaces, data management, and system integration, their core lies in a set of trained data models. These models possess the capability to handle complex tasks like speech-to-text conversion, image generation, translation, and open-ended conversations. However, maintaining these models often resembles the operations of service-based businesses and necessitates a significant amount of customized work for clients that goes beyond the scope of regular software development and technical support. This aligns with the challenges faced by AI companies. Depending on the stage of development, different companies employ various approaches to address operational challenges, but they all strive to find the right balance within the triangular relationship among shareholders, customers, and the company itself.
In the early stages of their journey, AI companies face a pressing need to identify pioneering scenarios that align with their technological capabilities, demonstrate technological advancement and business value, attract capital, and satisfy the board of directors. During this phase, growth often takes precedence over profitability. Within this context, AI companies frequently opt to invest their own workforce in manually cleaning and labeling datasets for the pioneering scenarios. The challenges associated with long-tail data are typically confined to specific scenarios until they meet delivery standards. It is observed that many AI startups maintain dedicated annotation and training teams. This stage of the business entails relatively rapid initial growth but with lower profit margins.
For AI companies, attaining product-market fit poses greater challenges compared to traditional software companies. Once they successfully acquire 5-10 customers, AI companies initially seek early customers that align with their technology. As new projects continue to increase, the company's machine learning team, algorithm engineers, and delivery managers start to encounter extended deployment cycles and a certain degree of project backlog. In the constrained resource environment of the company, the CEO or COO faces the decision of whether to continue acquiring new customers or prioritize timely delivery to existing customers.
In many instances, these challenges can be attributed to the realm of remote samples. While numerous AI applications can be packaged as API interfaces and seamlessly integrated with unprocessed unstructured data, model failures are not uncommon. As much as 40-50% of AI product functionality intentions are often found in the long tail of user intentions, making effective management of this vast case space an ongoing task. Each new customer deployment is likely to generate data that has never been encountered before. Furthermore, these deployment issues may not diminish over time. The optimal approach for AI companies at this stage is to secure additional time from company shareholders, such as through continued funding. Some AI companies also outsource the annotation work for specific long-tail samples to their clients or offer additional fee-based annotation and training services to their clients. This approach helps avoid positioning their business model as labor-intensive growth and limits the level of profit margins.
The rapid development of generative AI (GenAI) provides another avenue for AI companies to tackle the challenges of the long tail. This can be achieved by changing the technology stack or increasing investment in generative artificial intelligence resources. The rationale behind this approach lies in the fact that in many application areas of generative AI, the notion of model correctness becomes blurred. For example, the evaluation of whether a machine-generated image is "correct" varies from person to person. Similarly, determining the correctness of machine-generated Python source code often requires minor adjustments rather than a binary "0" or "1" evaluation. In these scenarios, users become part of the human-in-the-loop process, guiding the model towards the desired outcomes. This obviates the need for AI companies to maintain a dedicated operations team solely responsible for ensuring the immediate correctness of the model.
The emergence of GenAI has brought forth unexpected user behaviors accompanied by notable economic effects. Large-scale language models (LLMs) have been successfully applied in diverse domains such as software development, sales assistance, educational guidance, life coaching, friendship, and even romantic partnerships. These novel functionalities represent uncharted territories for computers and offer limitless possibilities for commercial applications. They also introduce a new equilibrium to the aforementioned "triangular relationship" or shared expectations for an unknown future.
While GenAI allows for a flexible interpretation of "accuracy," cleverly bypassing many challenges associated with the long tail of data, it presents the human involvement aspect as more acceptable to end users, fostering a shared goal between AI companies (technology providers) and users (technology users) to optimize results. However, it would be unrealistic to assume that the human cost is eliminated. A prudent approach entails establishing a sound business model and marketing strategy that prioritize model maintenance and human costs as critical considerations. It is crucial to fully identify and quantify the actual variable costs, ensuring they are transparent throughout the development process.
We recommend that AI companies carefully select specific technological application areas to focus on, often opting for narrower domains to reduce the complexity associated with data requirements. The amount of data needed for AI modeling is proportional to the breadth of the problem being addressed. Before initiating the data collection process, AI companies or AI product managers should consider narrowing the domain, avoiding the pursuit of building a "large-scale model" capable of handling any task.
Simultaneously, minimizing model complexity can be achieved through the implementation of a "single model" strategy, which includes simplifying maintenance, accelerating deployment to new customers, and streamlining MLOps to ensure efficiency. This approach often reduces data pipeline diffusion and redundant training runs, leading to significant improvements in training costs, encompassing computational power and cloud infrastructure, as previously mentioned.
The concept of an "MVP with 80-90% accuracy" holds substantial significance in the machine learning community. Machine learning algorithms often excel in partially solving various problems. For most problem domains, developing a model that achieves an accuracy level between 80% and 90% is relatively straightforward. Beyond this threshold, the return on investment in terms of time, resources, expertise, and data diminishes rapidly. As a rule of thumb, reaching 80% accuracy may require several months of effort, while achieving the remaining 20% may take several years or even longer.
Considering the current economic landscape, it may be more prudent for AI companies to prioritize being "roughly right" rather than aiming for precise perfection.
https://twitter.com/sama/status/1696286884803301605
[2] https://www.cnbc.com/2023/05/09/sclae-ai-disruptor-50.html